Research
Interactive Systems Research Description
Our research focuses on systems in which human interactions are a major component. Examples of interactive systems include education, medicine, games, fitness monitors, self-driving cars, interfaces to consumer electronics, and internet of things applications. These applications share a number of features, of which, the most important from the point of view of algorithmic development is that time-series data is typically undersampled with respect to the requirements for inference, leading to the need for causal models.
For example, consider the education problem. The knowledge graph of a typical engineering course is a directed acyclic graph (DAG) that is rooted in pre- requisites to the course, and proceeds through a sequence of concepts that depend in part on the pre-requisites and some of the concepts introduced earlier. A student’s learning process can also be modeled with a DAG that depends on a number of factors: study skills, mastery of prior content, time commitment, inherent learning ability, confounders (e.g., relationship or family trouble). The education “game” is a cooperative multi-agent game with partial observability. It is cooperative because the students and instructor have similar objectives: good performance on the tests with minimal time commitment. If the tests are carefully designed to measure understanding on the key concepts, then this results in a common objective of student learning. The students can see all the course materials, but with testing alone the instructor gets only periodic and partial sampling of what the student knows. The instructor cannot see into the student’s head; this asymmetry makes it essentially impossible to optimize the mutual strategies. However, there is another vital component in education: the one-on-one interaction in which the student and instructor come to a common understanding of why the student was having difficulty. With symmetry of information, the best intervention (or set of interventions) is usually obvious. This is why one-on-one tutoring has been shown in study after study to be more effective than any other teaching method. Unfortunately, it is not cost-effective. Therefore, the optimization problem in education is to maximize the percentage of a cohort that meets the basic requirement given the time resources of the instructor and the students.
As anyone who has taught in college for any period of time can attest, if one student shows up in office hours with some particular problem in understanding, the chances are high that there are many other students with the same problem. Thus, individual interactions can reveal important information about the cohort, allowing interventions for the class as a whole (e.g., going through another example, reviewing some pre-requisite material, assigning a quiz so that they actually study the concepts of interest). The structure of tests can influence the likelihood of students taking the necessary actions to improve understanding. The traditional midterm/final format does not give timely feedback, and can lead to students being in a deep hole. By contrast, a sequence of quizzes provides reasonably accurate weekly feedback on their progress, and can spur timely action by the students (e.g., group sessions with peers, office hours) that will quickly bring them back on track. Consequently there is not a clean separation between group and individual interventions, but it is clear that there is no way to optimize unless students themselves reveal the reasons for their difficulties to the instructor.
Where are the research challenges? Gathering ground truth is expensive in education, and one cannot try alternative interventions on the same person at the same time, i.e., explore alternative counterfactuals. By contrast, with a generative model, one can construct a simulation in which extensive exploration of counterfactuals is possible. If the generative model is complicated enough, one can investigate questions such as the number of samples/observations required to extend an approximate model, gather sufficient population data to characterize priors for subpopulations, and many other questions related to transfer learning and combining causal and deep learning models. More broadly, we are concerned with how to train models in a sample efficient manner, while preserving out of distribution generalization.
Publications (post 1999)
For list of prior publications, see Dr. Gregory Pottie’s CV
2024
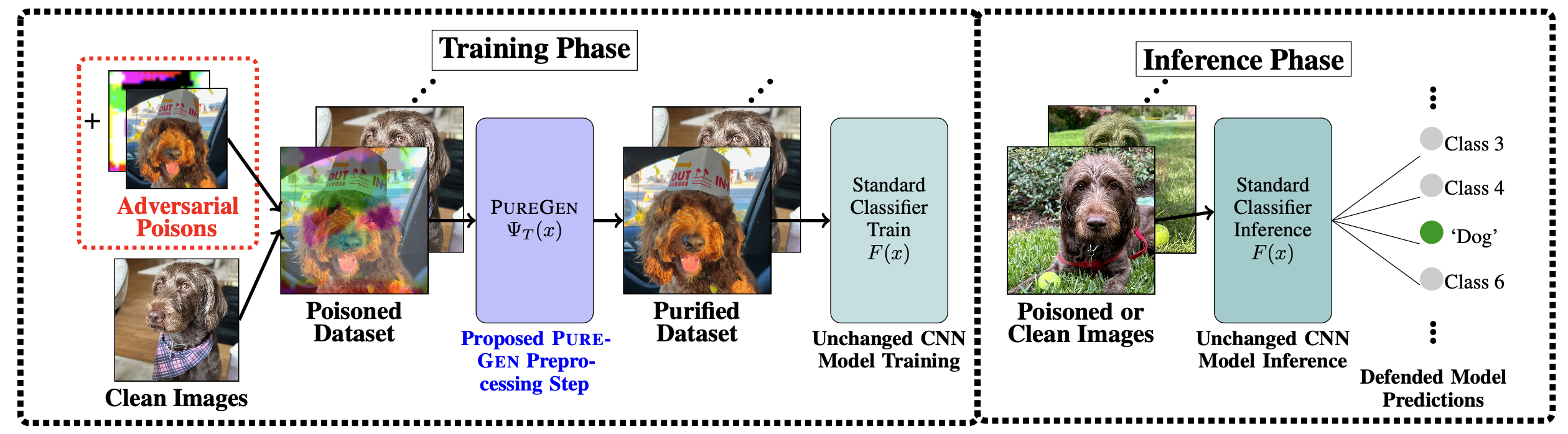
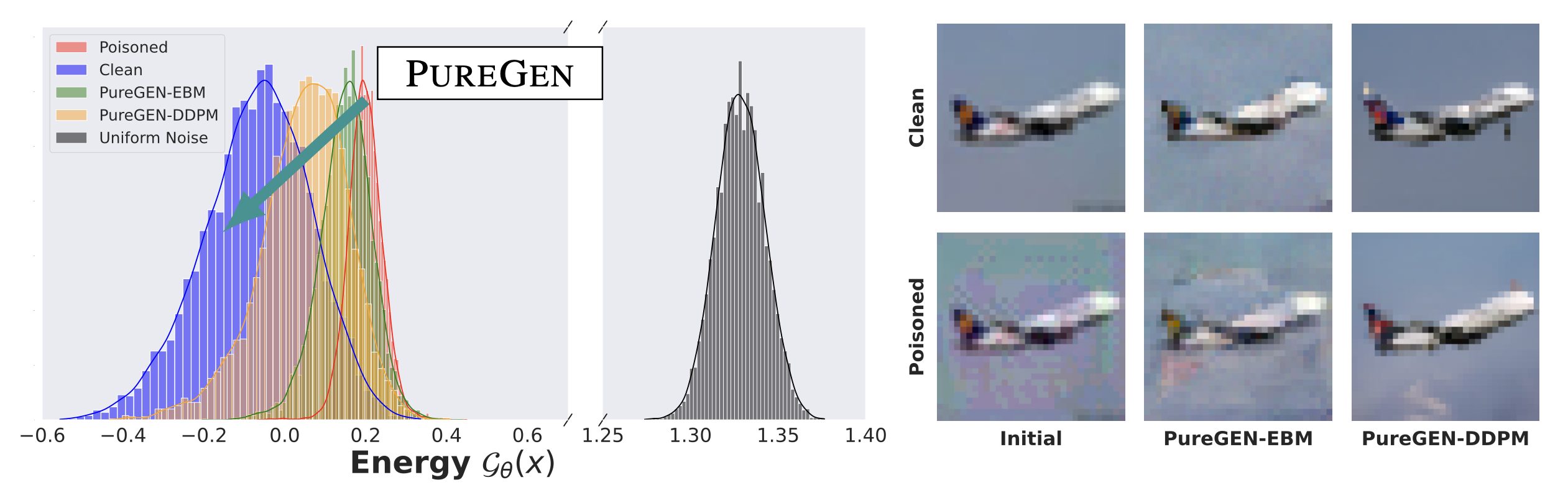
2023
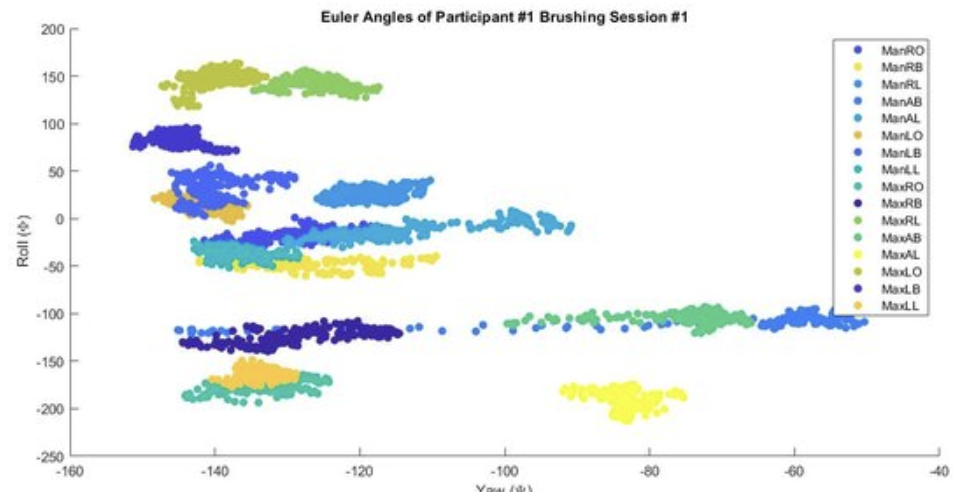
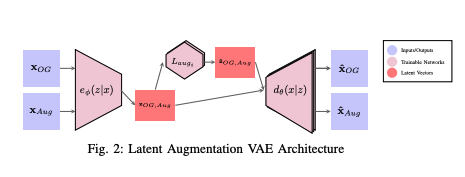
2022
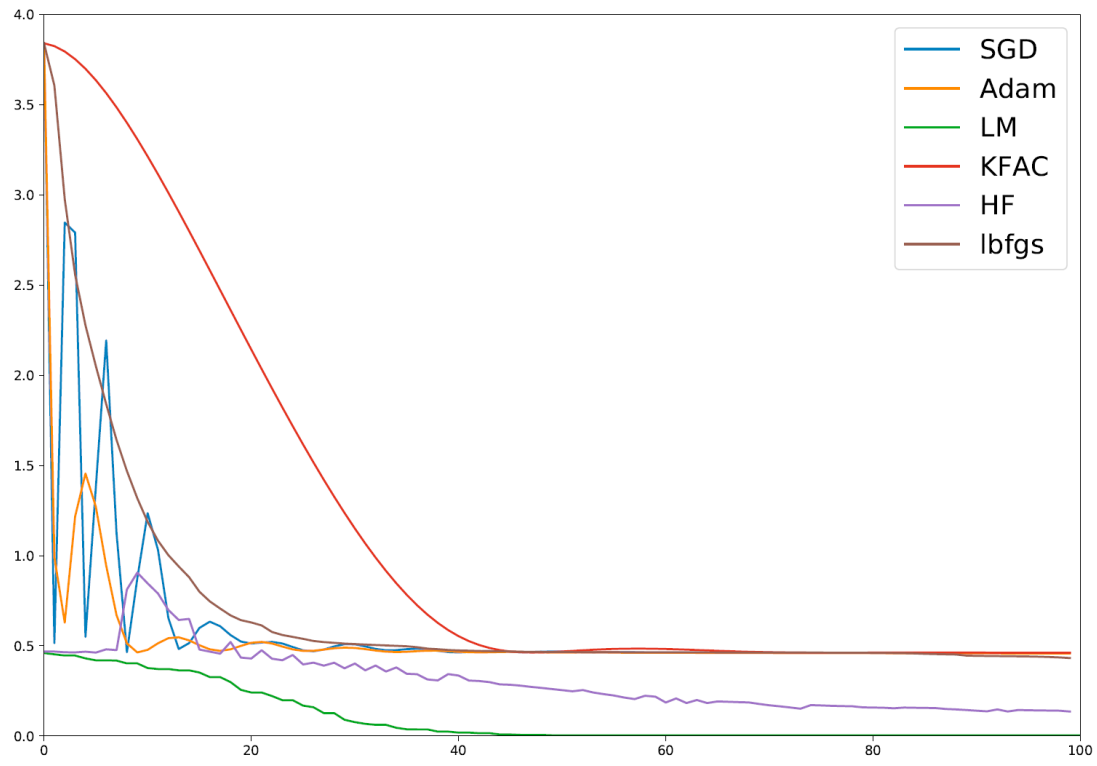

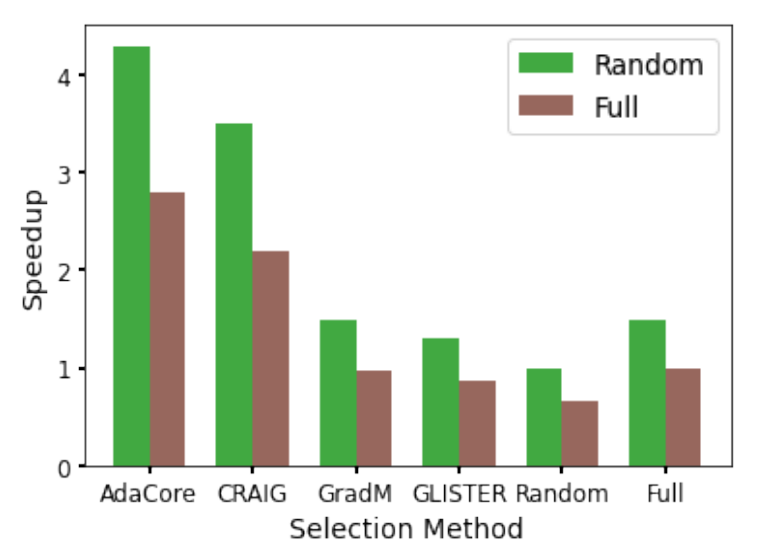
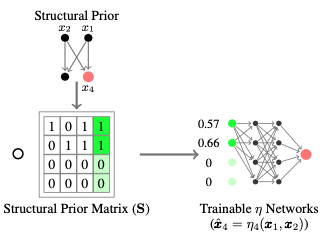
2020

2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2003
2002
2001
2000
1999